


Os LLMs nos permitiram processar grandes quantidades de dados de texto de forma muito eficiente, confiável e rápida. Um dos casos de uso mais populares que surgiram nos últimos dois anos é a Geração Aumentada de Recuperação (RAG).
O RAG nos permite pegar uma série de documentos (de alguns até cem mil), criar uma base de dados de conhecimento com os documentos e, em seguida, consultá-la e receber respostas com fontes relevantes com base nos documentos.
Em vez de ter que pesquisar manualmente, o que levaria horas ou até dias, podemos fazer com que um LLM nos procure com apenas alguns segundos de latência.
Baseado em nuvem versus local
Existem duas partes para fazer um sistema RAG funcionar: o banco de dados de conhecimento e o LLM. Pense no primeiro como uma biblioteca e no segundo como um funcionário de biblioteca muito eficiente.
A primeira decisão de design ao criar tal sistema é se você deseja hospedá-lo na nuvem ou localmente. As implantações locais têm uma vantagem de custo em escala e também ajudam a proteger sua privacidade. Por outro lado, a nuvem pode oferecer baixos custos iniciais e pouca ou nenhuma manutenção.
Para demonstrar claramente os conceitos em torno do RAG, optaremos por uma implantação na nuvem durante este guia, mas também deixaremos notas sobre como se tornar local no final.
O banco de dados de conhecimento (vetorial)
Portanto, a primeira coisa que precisamos fazer é criar um banco de dados de conhecimento (tecnicamente chamado de banco de dados vetorial). A forma como isso é feito é executando os documentos por meio de um modelo de incorporação que criará um vetor a partir de cada um. Os modelos de incorporação são muito bons para compreender texto e os vetores gerados terão documentos semelhantes mais próximos no espaço vetorial.
Isso é incrivelmente conveniente e podemos ilustrá-lo plotando os vetores de quatro documentos de uma organização hipotética em um espaço vetorial 2D:
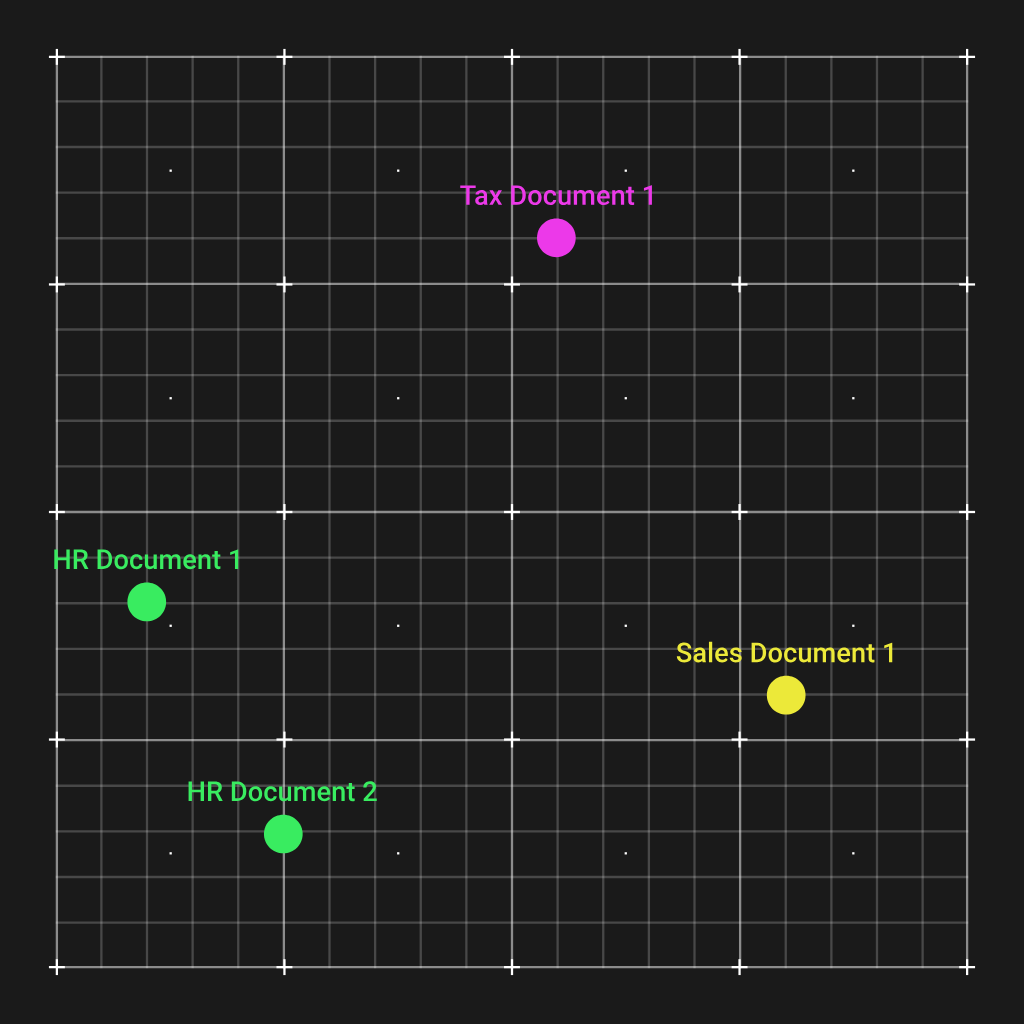
Como você pode ver, os dois documentos de RH foram agrupados e estão distantes dos demais tipos de documentos. Agora, a forma como isso nos ajuda é que quando tivermos uma pergunta sobre RH, podemos calcular um vetor de incorporação para essa pergunta, que também terminará próximo aos dois documentos de RH.
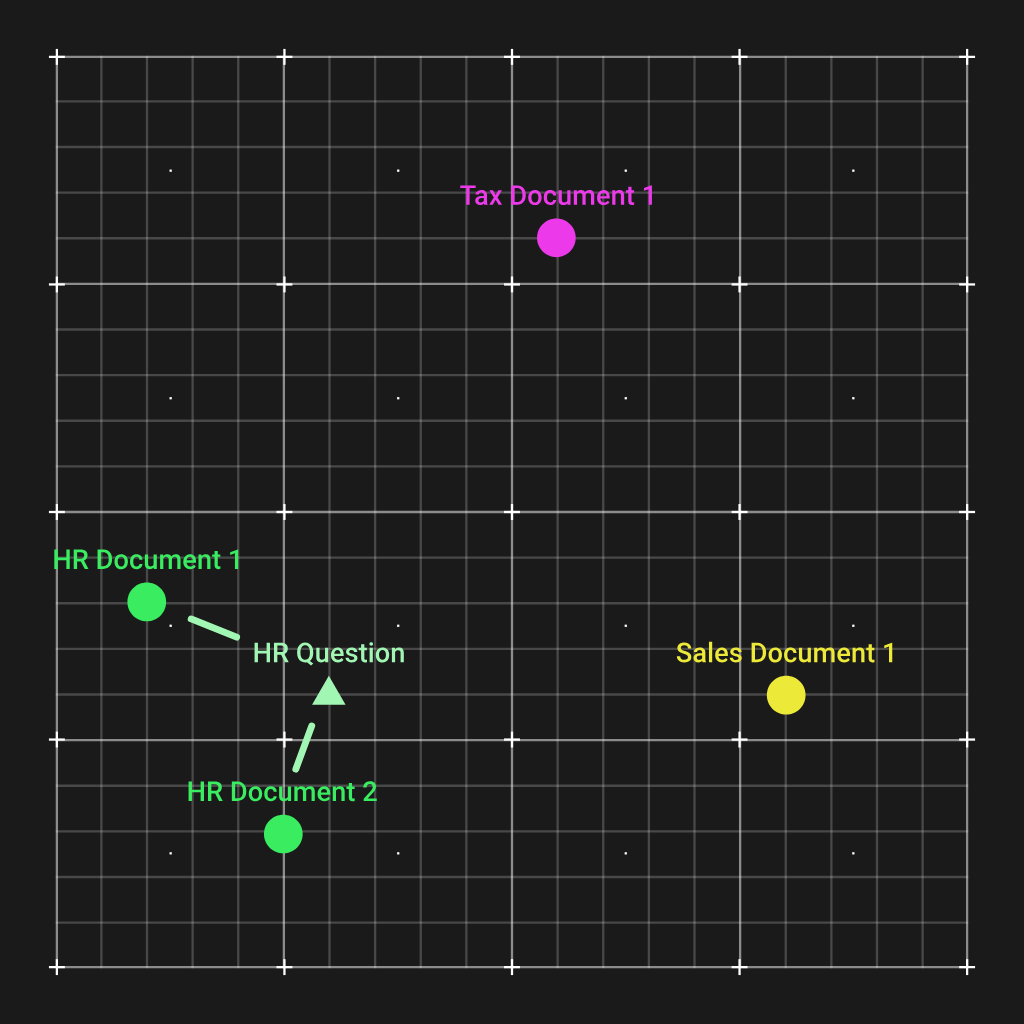
E por meio de um simples cálculo da distância euclidiana, podemos combinar os documentos mais relevantes para entregar ao LLM para que ele possa responder à pergunta.
Há uma vasta gama de algoritmos de incorporação para escolher, todos comparado na tabela de classificação do MTEB. Um fato interessante aqui é que muitos modelos de código aberto estão assumindo a liderança em comparação com fornecedores proprietários como o OpenAI.
Além da pontuação geral, mais duas colunas a serem consideradas nessa tabela de classificação são o tamanho do modelo e o máximo de tokens de cada modelo.
O tamanho do modelo determinará quanto V(RAM) será necessário para carregar o modelo na memória, bem como quão rápido serão os cálculos de incorporação. Cada modelo só pode incorporar uma certa quantidade de tokens, portanto, arquivos muito grandes podem precisar ser divididos antes de serem incorporados.
Por último, os modelos só podem incorporar texto, portanto, quaisquer PDFs precisarão ser convertidos, e elementos ricos como imagens devem ser legendados (usando um modelo de legenda de imagem AI) ou descartados.
Os modelos de incorporação local de código aberto podem ser executado localmente usando transformadores. Para o modelo de incorporação OpenAI, você precisará de um Chave de API OpenAI em vez disso.
Aqui está o código Python para criar embeddings usando a API OpenAI e um banco de dados vetorial simples baseado em sistema de arquivos pickle:
import os
from openai import OpenAI
import pickle
openai = OpenAI(
api_key="your_openai_api_key"
)
directory = "doc1"
embeddings_store = {}
def embed_text(text):
"""Embed text using OpenAI embeddings."""
response = openai.embeddings.create(
input=text,
model="text-embedding-3-large"
)
return response.data(0).embedding
def process_and_store_files(directory):
"""Process .txt files, embed them, and store in-memory."""
for filename in os.listdir(directory):
if filename.endswith(".txt"):
file_path = os.path.join(directory, filename)
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
embedding = embed_text(content)
embeddings_store(filename) = embedding
print(f"Stored embedding for {filename}")
def save_embeddings_to_file(file_path):
"""Save the embeddings dictionary to a file."""
with open(file_path, 'wb') as f:
pickle.dump(embeddings_store, f)
print(f"Embeddings saved to {file_path}")
def load_embeddings_from_file(file_path):
"""Load embeddings dictionary from a file."""
with open(file_path, 'rb') as f:
embeddings_store = pickle.load(f)
print(f"Embeddings loaded from {file_path}")
return embeddings_store
process_and_store_files(directory)
save_embeddings_to_file("embeddings_store.pkl")
LLM
Agora que temos os documentos armazenados no banco de dados, vamos criar uma função para obter os 3 documentos mais relevantes com base em uma consulta:
import numpy as np
def get_top_k_relevant(query, embeddings_store, top_k=3):
"""
Given a query string and a dictionary of document embeddings,
return the top_k documents most relevant (lowest Euclidean distance).
"""
query_embedding = embed_text(query)
distances = ()
for doc_id, doc_embedding in embeddings_store.items():
dist = np.linalg.norm(np.array(query_embedding) - np.array(doc_embedding))
distances.append((doc_id, dist))
distances.sort(key=lambda x: x(1))
return distances(:top_k)
E agora que temos os documentos vem a parte simples, que leva nosso LLM, GPT-4o neste caso, a dar uma resposta com base neles:
from openai import OpenAI
openai = OpenAI(
api_key="your_openai_api_key"
)
def answer_query_with_context(query, doc_store, embeddings_store, top_k=3):
"""
Given a query, find the top_k most relevant documents and prompt GPT-4o
to answer the query using those documents as context.
"""
best_matches = get_top_k_relevant(query, embeddings_store, top_k)
context = ""
for doc_id, distance in best_matches:
doc_content = doc_store.get(doc_id, "")
context += f"--- Document: {doc_id} (Distance: {distance:.4f}) ---\n{doc_content}\n\n"
completion = openai.chat.completions.create(
model="gpt-4o",
messages=(
{
"role": "system",
"content": (
"You are a helpful assistant. Use the provided context to answer the user’s query. "
"If the answer isn't in the provided context, say you don't have enough information."
)
},
{
"role": "user",
"content": (
f"Context:\n{context}\n"
f"Question:\n{query}\n\n"
"Please provide a concise, accurate answer based on the above documents."
)
}
),
temperature=0.7
)
answer = completion.choices(0).message.content
return answer
Conclusão
Aí está! Esta é uma implementação intuitiva do RAG com muito espaço para melhorias. Aqui estão algumas ideias sobre onde ir a seguir:
